Introdução
Policiamento preditivo pode ser definido pela aplicação de técnicas analíticas de identificação para direcionar a intervenção policial na prevenção de crimes, utilizando previsões estatísticas. A ideia é que seja possível prever quando e onde atividades criminosas ocorrerão, por meio de algoritmos e da inteligência artificial, como é o caso do programa PredPol. Todavia, a aplicação deste método é questionável, haja vista a possibilidade de enviesamento dos dados fornecidos, situação que resultaria, por exemplo, em ações policiais excessivas num determinado bairro ou região.
Nesse sentido, foi feita uma análise de bibliográfica a respeito do policiamento preditivo. Mais especificamente, analisou-se o mencionado programa a partir do artigo publicado pela Royal Statistical Society que demonstrou a falta de ineficácia do método preditivo em razão do uso de dados enviesados pelos sistemas de predição. Logo, a aplicabilidade do método preditivo de policiamento deve ser estudada com meticulosidade pois o impacto social discriminatório causado pelo seu mal uso, é notório, conforme expos o presente trabalho.
Policiamento Preditivo
O direito penal estuda formas de amparar as relações sociais por meio de normas que estipulam condutas consideradas ilícitas para o ordenamento jurídico adota. De fato, se fosse possível prever o futuro, muitas das teorias e doutrinas criadas seriam descartáveis, porque bastaria impedir a prática reprovável antes mesmo que ela ocorresse. Todavia, as inovações tecnológicas abriram espaço para a criação de mecanismos como o algoritmo, definido por um conjunto de métodos utilizados na realização de cálculos, resolução de problemas e na tomada de decisões, por exemplo.
Sua definição, pode ser explicada por uma analogia da receita culinária. O algoritmo seria a receita, como de uma sopa de legumes, enquanto o passo a passo seria sua programação (separar os legumes, esquentar a água, temperar etc.).[1] Isto, deflagra que algoritmos de aprendizado automático são projetados para armazenarem, calcularem e reproduzirem padrões somente a partir dos dados fornecidos, independentemente se os resultados representarão ou não aquilo esperado. Logo, entre os fatores principais do policiamento preditivo é correto apontar a programação do algoritmo, os dados utilizados pelo programa e para qual fim este método será empregado.
Os Estados Unidos é um dos pioneiros dos métodos preditivos, além do PredPol, foi onde lançaram-se programas como o Palantir, o CrimeScan e o ShotSpotter Missions. Vale destacar a definição dada por Charlie Beck, chefe de detetives da Polícia de Los Angeles acerca do policiamento preditivo, observe:
“Com a nova tecnologia, novos processos de negócios e novos algoritmos, o policiamento preditivo é baseado em patrulha direcionada e baseada em informações; resposta rápida suportada pelo posicionamento prévio de ativos com base em fatos; e táticas, estratégias e políticas proativas, baseadas em inteligência. A era do policiamento preditivo promete resultados mensuráveis, incluindo a redução do crime; agências policiais mais eficientes; e policiamento moderno e inovador. A análise avançada inclui a revisão e análise sistemática de dados e informações usando métodos automatizados. Através do uso de gráficos exploratórios em combinação com estatísticas avançadas, ferramentas de aprendizado de máquina e inteligência artificial, informações críticas podem ser identificadas e extraídas de grandes repositórios de dados. Ao investigar os dados dessa maneira, é possível provar ou refutar hipóteses ao descobrir informações novas ou previamente desconhecidas. Em particular, relacionamentos, tendências, padrões, sequências e afinidades únicos ou valiosos nos dados podem ser identificados e usados proativamente para categorizar ou antecipar ações ou informações adicionais”.[2]
Por outro lado, a efetividade apontada por Beck é refutada por não haver evidências reais de que algoritmos preditivos promovem a segurança pública. A justificativa para isso, seria a presunção equivocada de as entradas, isto é, as informações fornecidas ao algoritmo, serão neutras. Espera-se que as informações geradas pelo programa sejam objetivas e imparciais, porém, isso depende exclusivamente da precisão das informações fornecidas ao algoritmo.[3]
Por este caminho, crimes ocorridos em locais frequentados pela polícia, estão mais propensos a serem apontados pelo algoritmo, simplesmente porque é onde a polícia normalmente patrulha. Além disso, é fato que os registros policiais não contêm informações sobre todos os crimes que ocorrem, muitos não são denunciados, o que influenciaria diretamente na análise algorítmica. Para confirmar essa tese, bastaria dar o exemplo de crimes relacionados a drogas, como a maconha, porque sabe-se que negros e latinos são presos, processados e condenados por tais crimes em proporções muito maiores do que brancos, mesmo que o uso de entorpecentes por ambas as partes seja em proporções similares.[4]
Desta forma, se os resultados dos programas de policiamento preditivo dependem do fornecimento preciso de dados, não seria errado dizer que caso um algoritmo seja alimentado com dados irreais, como o número de prisões entre negros/latinos e brancos em crimes relacionados a maconha, a previsão feita também possuirá vieses.
PredPol
Originalmente, a companhia objeto de estudo surgiu de um projeto de pesquisa realizado pelo Departamento de Polícia de Los Angeles (LAPD) e a Universidade da Califórnia em Los Angeles (UCLA). Bill Bratton, diretor do projeto, organizou uma equipe que estudava dados e modelos comportamentais e de previsão, com auxílio de analistas criminais e de policiais da LAPD.[5]
Da pesquisa, foram determinados os três pontos mais precisos dos dados coletados para a previsão: o tipo de crime, o local, a data e a hora. A ideia é que se identifique os horários e locais onde os crimes específicos terão maior probabilidade de ocorrer, majorando o patrulhamento nas áreas identificadas como resposta. Tais previsões, são calculadas a partir de informações de vitimização, isto é, das denúncias armazenadas em bancos de dados policiais.[6]
Além disso, a empresa também aponta três aspectos do comportamento dos criminosos adotado pelo algoritmo. Vale transcrever aquilo exposto pelo site oficial da empresa:
“1. Repita a vitimização, que descreve - tomando como exemplo o roubo - que, se uma casa for invadida hoje, o risco de ser invadida amanhã aumentará. Isso ocorre porque é "racional" que os infratores retornem aos lugares onde tiveram sucesso antes. Faz menos sentido ir a alguma outra casa desconhecida, onde eles não sabem se a casa está vazia, não sabem o quão difícil é invadir e não sabem o que há para ser roubado. A casa em que invadiram dois ou três dias atrás é muito menos arriscada.
2. Vitimização quase repetida, que reconhece que não apenas sua casa está em maior risco de ser arrombada novamente, mas a casa de seu vizinho também está em maior risco. Seu vizinho é muito parecido com você: eles têm status socioeconômico semelhante, trabalham horas semelhantes, têm uma casa muito parecida com a sua e terão o mesmo material para roubar. O 'script' ofensivo que o agressor usava para invadir os mapas da sua casa quase perfeitamente.
3. A pesquisa local une tudo isso. Sabemos que os infratores raramente viajam muito longe de seus principais pontos de atividade, como casa, local de trabalho e lazer, o que significa que os crimes tendem a se agrupar”.[7]
Tratado do perfil dos agressores, o PredPol usa os sistemas de gerenciamento de registros (RMS) das agências que o contratam para extrair dados de crimes e seus históricos, estes que alimentarão o algoritmo que criará as previsões. Essa extração decorre da análise de cinco pontos, o primeiro deles é o identificador de incidente, onde é feita uma identificação exclusiva para o crime analisado pelo algoritmo. Em segundo lugar, definir o tipo de crime ou evento ilícito, ou seja, a tipificação legal dessa conduta reprovável.[8]
Localizar o incidente é o terceiro ponto, definir a latitude e longitude pelo sistema WGS 84, ou, se caso não for disponível, o nome da rua, cidade, estado e região dos crimes ocorridos. O quarto ponto pode ser considerado um subponto do terceiro, pois menciona que caso não seja possível definir a data e hora exata do crime, é possível definir seu lapso temporal de ocorrência, ou seja, o ponto de início e término da atividade ilegal. Por fim, a empresa pode solicitar dos contratantes que seja disponibilizado registro modificado de data/hora, para indicar se os registros dos crimes, como seu código, passaram por alterações ou reclassificações.[9]
Kristian Lum e William Isaac, cientes do ramo preditivo de policiamento, questionam: “mas o que acontece quando esses sistemas são treinados pelo uso de dados tendenciosos?”. Isto surgiu em razão do caso de Robert McDaniel, residente da cidade de Chicago, que recebera uma visita inesperada de um comandante do departamento de polícia avisando-o para não cometer mais nenhum crime futuramente. Contudo, Robert nunca havia cometido crimes, sequer possuía uma ficha criminal, tampouco havia tido contato com oficiais da lei, então por que da visita?[10]
A resposta para essa questão foi a de que McDaniel seria uma entre as quatrocentas pessoas da “heat list” ou “lista de calor” do departamento de polícia de Chicago. De fato, previu-se que esses indivíduos estariam potencialmente envolvidos em crimes violentes, com base na localização geográfica e de dados de prisões, isto é, “big data”. Por essa razão, os autores apontaram que o policiamento preditivo levantas sérias preocupações como: conflitos com as proteções contra buscas e apreensões ilegais e o conceito de suspeita razoável; falta de transparência, tanto dos departamentos de polícia quanto de empresas privadas para a construção de modelos preditivos; como são usados os dados e se os programas direcionam desnecessariamente grupos específicos mais do que outros.[11]
Outra preocupação importante apontada por Lum e Isaac no artigo de análise, é sobre a possibilidade dos dados registrados pela polícia (utilizados pelos algoritmos) estrem repletos de preconceitos sistemáticos. Isso significa que, se o software de policiamento preditivo foi projetado para aprender e reproduzir padrões a partir dos dados fornecidos, se forem usados dados tendenciosos para seu treinamento, serão reproduzidos e, em alguns casos, amplificados esses vieses. Logo, na melhor das hipóteses os sistemas de policiamento preditivos serão ineficazes, por outro lado, o pior cenário seria o aumento do policiamento discriminatório.[12]
A primeira parte da pesquisa menciona sobre os vieses nos registros e dados policiais. Pontua-se que, ao menos desde o século XIX, pesquisas criminológicas apontam que bancos de dados policiais não são um censo completo de todos os crimes cometidos. Além disso, evidencias empíricas sugerem que policiais, implícita ou explicitamente, consideram raça e etnia quando determinam quais pessoas deter e em quais bairros patrulhar.[13]
Sendo assim, se a polícia focaliza grupos éticos e bairros específicos nas patrulhas é provável que os registros policiais representem sistematicamente os mesmos grupos e bairros. Desta forma, é mais provável que crimes que ocorrem em locais mais frequentados pela polícia apareçam nos resultados do algoritmo simplesmente porque é onde a polícia normalmente patrulha. Tal viés nos dados policiais também decorre do nível de confiança comunidade na polícia e à quantidade desejada de policiamento no local, variando de acordo com a localização geográfica e a composição demográfica dessas comunidades.[14]
Isso deflagra que outras fontes de preconceito podem ocorrer através das denúncias da comunidade, não só da polícia. Válido destacar também a definição de policiamento preditivo feita pela RAND Corporation, apontada pelo artigo, sendo uma “aplicação de técnicas analíticas - particularmente técnicas quantitativas - para identificar alvos prováveis para intervenção policial e prevenir crimes ou resolver crimes passados, fazendo previsões estatísticas”. Esse método é o mesmo usado por outras empresas como a Amazon e a Facebook por exemplo, utilizando informações dos consumidores para veicular anúncios e produtos de relevância.[15]
O estudo realizado por Lum e Isaac se dá pela análise de uma população sintética. Esta, trata-se de uma representação individual demograficamente precisa de uma população real, no caso, os cidadãos de Oakland/CA. São apontados o sexo, renda familiar, a idade, raça e coordenações geográficas das residências; isso para que as características demográficas na população sintética se equiparem aos dados do censo dos EUA na maior resolução geográfica possível. É exposto o seguinte:
“Para combinar a pesquisa da NSDUH [National Survey on Drug Use and Health] com nossa população sintética, primeiro, ajustamos o modelo aos dados da NSDUH que prevê a probabilidade do uso individual de drogas no último mês com base em suas características demográficas (sexo, renda familiar, idade e raça). Então, aplicamos esse modelo a cada indivíduo da população sintética para obter uma probabilidade estimada de uso de drogas para cada pessoa sintética em Oakland. Estas estimativas baseiam-se no pressuposto de que a relação entre o uso de drogas e as características demográficas é a mesma em nível nacional como em Oakland. Embora isso provavelmente não seja totalmente verdade, o conhecimento contextual sobre a cultura local em Oakland nos leva a acreditar que, no máximo, o uso de drogas é ainda mais amplamente distribuído do que o indicado pelos dados em nível nacional”.[16]
Mais adiante, abordando sobre o funcionamento dos softwares e algoritmos de predição policial, cita-se o caso da máquina “Tay”. Foi necessário apenas esforço coordenado de usuários para assediar Tay com um número gigante de “tweets” misóginos e ofensivos, a consequência disso, em um dia a conta Tay havia sido suspensa porque estaria gerando tweets com o mesmo conteúdo desagradável.[17]
Outro exemplo é o da Google Flu Trends, serviço que pretendia prever a intensidade e a localização de surtos de gripe, por meio do “machine learning”. Com o eventual fracasso da pandemia de gripe A – H1N1 ter passado despercebido, apontam como motivo para tal, alterações internas dos sistemas de recomendação do Google, que indicavam consultas a pessoas sem sintomas de gripe. O interessante é que, neste caso, a causa para o enviesamento dos dados foi autoinduzida, sem a necessidade de boicotes por usuários. Foram propagados dados com excesso de consultas relacionadas à gripe, como resultado, o Google Fly Trends passou a deduzir casos de gripes onde não havia.[18]
Neste diapasão, os dois exemplos evidenciam que o problema não está no algoritmo ou programa de predição, mas sim nos dados usados. O algoritmo se comporta normalmente, porém, esses dados são coletados como um subproduto da atividade policial, de maneira que as previsões feitas com base naqueles dados não pertencem a casos futures de crime. Na verdade, tratam de futuros casos de crime que se tornam conhecidos pela polícia, logo, o policiamento preditivo está prevendo o policiamento futuro, e não o crime futuro.[19]
Isto ainda pode se agravar pelo fato de os departamentos policiais usarem previsões tendenciosas para tomar decisões de policiamento. Em outras palavras, os policiais estão mais propensos a patrulhar as mesmas áreas já conhecidas, observando novos atos criminosos, o que confirma sua tese sobre a habitualidade de atividades criminosas no local. Ao final, os atos criminosos mais recentes, serão registrados pelas patrulhas direcionadas e consequentemente alimentarão o algoritmo, que reproduzirá previsões cada vez mais tendenciosas.
Para provar quão tendenciosos são os dados, seria preciso comparar os crimes registrados nos bancos de dados policiais com um registro completo de todos crimes ocorridos. Isso é uma tarefa extremamente complicada, pois como já aduzido, muitos crimes sequer são denunciados, impossibilitando qualquer registro ou indicação sobre.
A solução adotada pelo estudo ante tal obstáculo, foi de combinar a população sintética mencionada anteriormente com os dados da Pesquisa Nacional sobre Uso e Saúde de Drogas (NSDUH) realizada em 2011. Após isso, descobriu-se que os crimes de drogas conhecidos pela polícia não são uma amostra representativa real de todos os crimes relacionados a drogas.
Em seguida, o artigo esboça as seguintes imagens:
Imagem 1
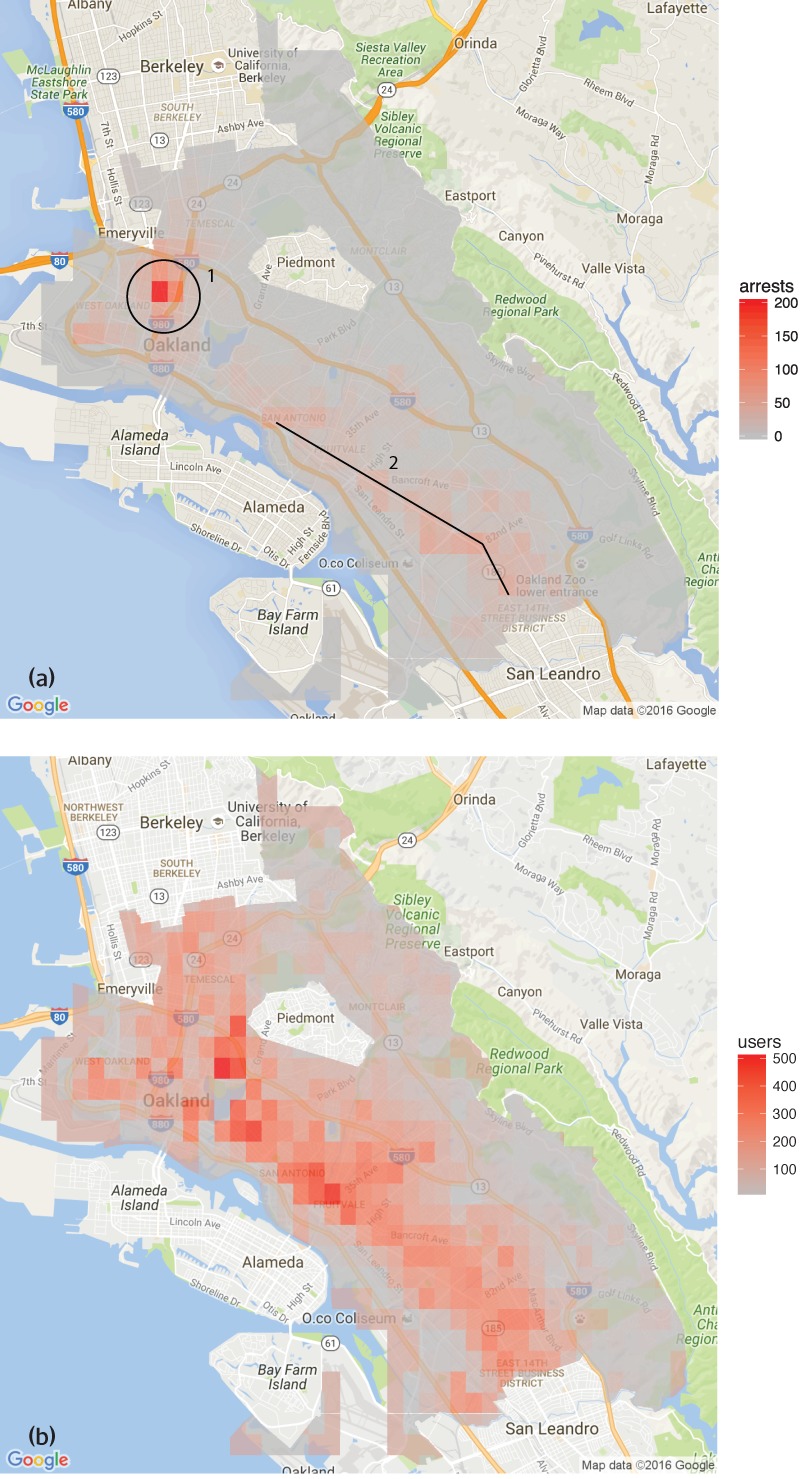
A Imagem 1[20] mostra:
(a) a quantidade de detenções envolvendo drogas, por área, em 2010, com base nos dados obtidos pelo Departamento de Polícia de Oakland;
(b) o número estimado de usuários de drogas por área, conforme índice ao lado.
Ao compará-las, ficou claro que os bancos de dados policiais e as estimativas da saúde pública apontam diferentes realidades sobre o padrão de uso de drogas na cidade.[21]
Ademais, a Imagem 1 – (a), as zonas quentes se situam entre bairros nos arredores de West Oakland e International Boulevard (pontos 1 e 2). Não por acaso, essas regiões possuem uma população predominantemente negra, latina e de baixa renda, bairros que “experimentam cerca de 200 vezes mais prisões relacionadas a drogas do que outras áreas”.
Todavia, a Imagem 1 – (b) indica zonas quentes mais espalhadas, não apenas em dois bairros, mas por toda a cidade, indicando que mesmo que crimes relacionados a drogas ocorram em diversos lugares, as detenções relativas a eles ocorrem somente em áreas específicas.[22]
A fim de comprovar a ideia, aplicou-se o algoritmo PredPol no banco de dados da polícia de Oakland para obter uma previsão de crime de drogas na cidade no ano de 2011. Foi registrado quantas vezes cada zona quente teria sido apontada pelo algoritmo, seu resultado é demonstrado a seguir:
Imagem 2
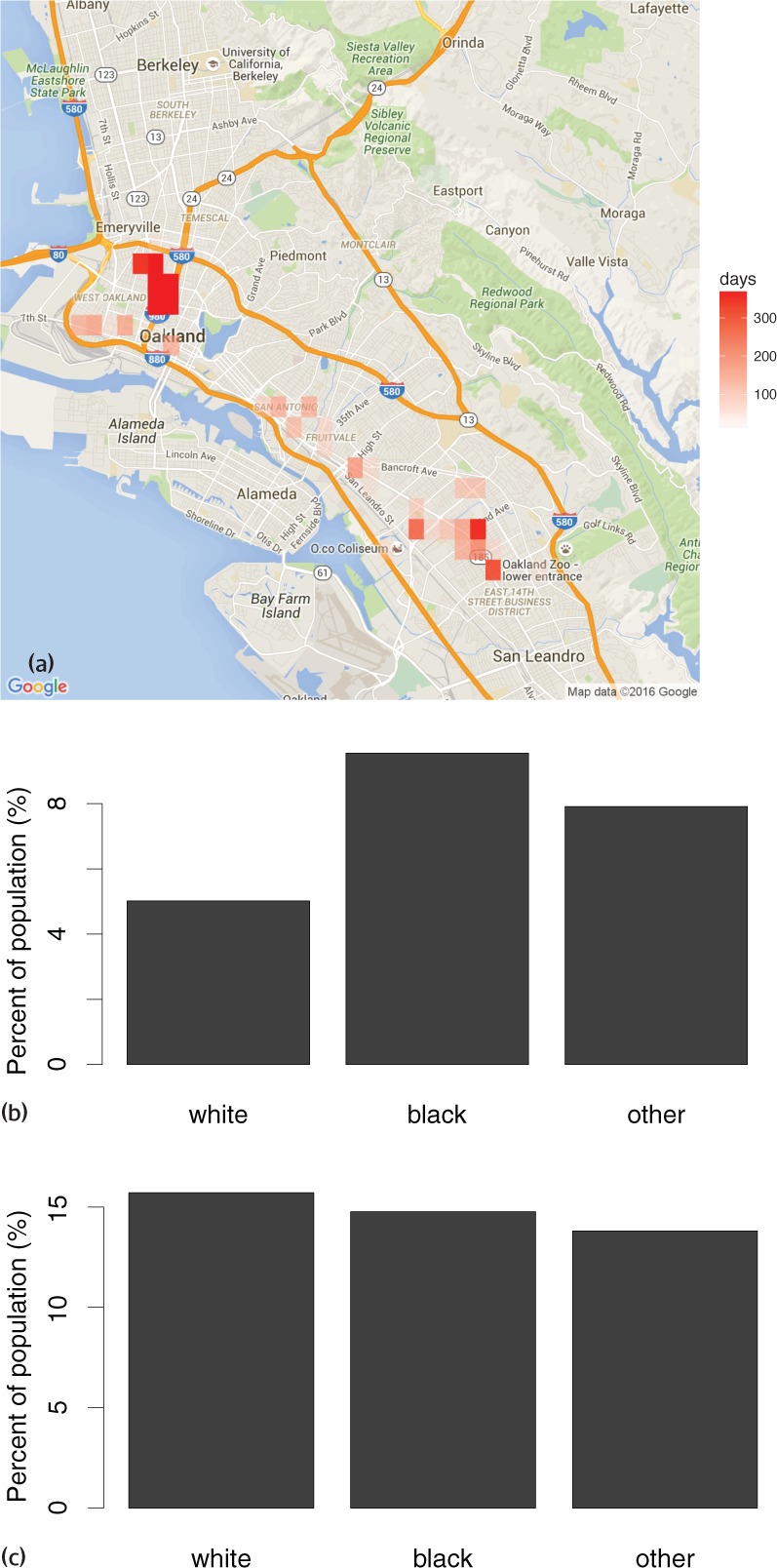
Na Imagem 2[23] temos:
(a) “número de dias de policiamento direcionado para crimes relacionados a drogas, com base no banco de dados policiais de Oakland usado pelo PredPol”;
(b) “porcentagem da população direcionada pelo policiamento para crime de drogas, por raça”;
(c) “porcentagem do uso estimado de drogas, por raça”.[24]
Diante disso, é possível afirmar que ao invés do programa corrigir os vieses aparentes contidos nos dados policiais, eles os reforçam. Com efeito, os locais indicados para policiamento direcionado são as mesmas áreas que já sofrem com números desproporcionais de detenções se comparados a outras localidades.
A imagem 2 – (b) aponta que, se o PredPol fosse usado em Oakland, as pessoas negras teriam duas vezes mais chances de serem alvos do policiamento preditivo do que pessoas brancas. Em contraste a isso, a imagem 2 – (c) aponta que o uso de drogas é praticamente o mesmo entre as classificações raciais.[25]
Esse mesmo resultado é obtido caso a análise seja feita pelo grupo de renda, pois grupos de baixa renda enfrentam uma taxa de policiamento direcionado desproporcionalmente alta em relação aos demais grupos. Assim, o resultado disso seria um policiamento desproporcional nas comunidades de baixa renda e de maioria negra e latina. [26]
Outro ponto importante, é de que existe a possibilidade de policiais receberem incentivos para aumentar sua produtividade a partir da demanda. Isto, caso ocorresse, os influenciaria a procurar oportunidades adicionais para efetuar prisões. Logo, é compreensível pensar que quanto mais tempo a polícia patrulhar, mais crimes poderão ser encontrados neste mesmo lugar. O artigo analisado também expõe um gráfico que simula possíveis consequências deste cenário que vale a pena conferir.[27]
Imagem 3
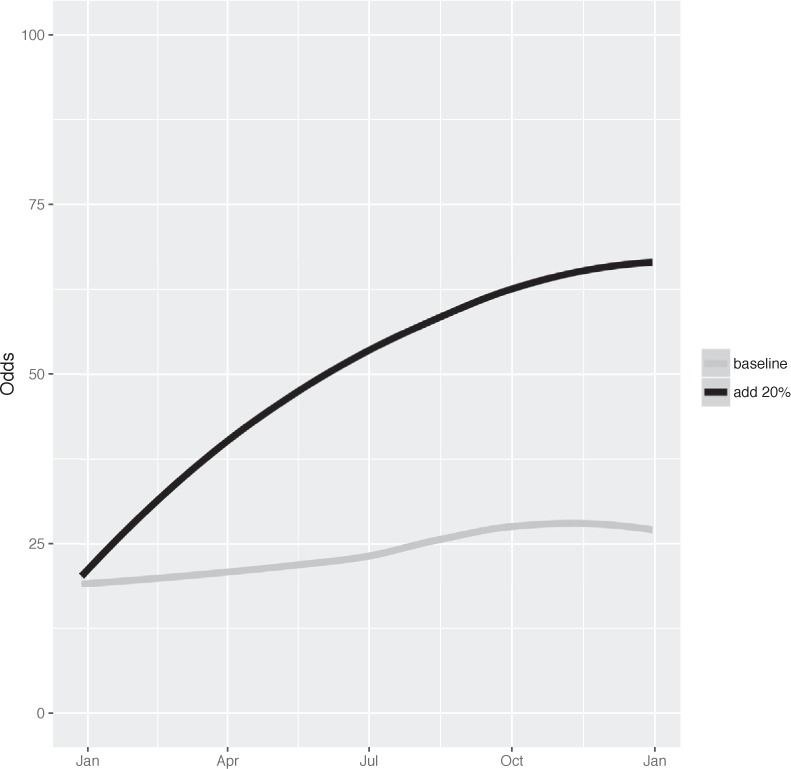
Lum, a partir do estudo, afirma que se a polícia patrulhar um local e encontrar mais crimes, isso criaria um ciclo de feedback, pois aumentaria a certeza do algoritmo de que nesse lugar ocorrerão mais crimes. Para mais, sabendo que o algoritmo usa denúncias de crimes e prisões para gerar alvos direcionados (zonas quentes), suas recomendações podem se tornar autorrealizáveis.[28]
Importante mencionar também o estudo realizado por Matt Kusner e sua equipe do Instituto Alan Turing, em Londres. Foi criado um modelo matemático simplificado do software PredPol, que escolhe como distribuir um certo número de oficiais entre dois locais, ao passo que, se mais forem enviados para um local, eles tendem a fazer mais prisões lá. Como resultado, a equipe descobriu que quando isso é devolvido ao sistema, ele tendenciosamente envia ainda mais oficiais para o mesmo local, comprovando o ciclo de feedback supracitado.[29]


